 |
waLBerla 7.2
|
|
waLBerla 7.2
|
WaLBerla is a high-performance computing framework that supports GPU computing using either CUDA or HIP. In this tutorial, we will provide an overview of the GPU concepts in WaLBerla and show you how to create GPU fields and write GPU kernels using the provided indexing strategies.
waLBerla supports GPUs through a simple wrapper around both CUDA and HIP libraries. This allows users to write GPU-accelerated code that can run on both NVIDIA and AMD GPUs. In the following we will explain the concept with a simple example on how to allocate memory on GPUs. To create and manage GPU memory in waLBerla, the gpuMalloc function should be used always, which is defined depending on the build system used to compile waLBerla. Specifically, if waLBerla was built with CUDA, gpuMalloc is defined as cudaMalloc, while if it was built with HIP, gpuMalloc is defined as hipMalloc. This allows users to write GPU-accelerated code that can run on both NVIDIA and AMD GPUs. Here's an example of how to create a GPU array of 100 floats and set its values to zero using waLBerla:
In conclusion, waLBerla provides a simple wrapper around both CUDA and HIP libraries to allow users to write GPU-accelerated code that can run on both NVIDIA and AMD GPUs. This wrapper is used through the entire backend of waLBerla and thus for all higher level functionality. As a user most of the time the higher level functionality will be used and the wrapper is more important for developers. As a next step and introduction to some of the higher level functionality follows.
To create a GPU field in WaLBerla, you can use the gpu::GPUField class, which is similar to the field::GhostLayerField class used for CPU fields. You can copy data between the host and device using the gpu::fieldCpy function, as shown in the following example:
Note that gpu::GPUField has a template parameter for the number of fields (or channels), whereas field::GhostLayerField has a template parameter for the size of each field. Also, GPU fields can be accessed using gpu::FieldAccessor objects, which we will discuss next.
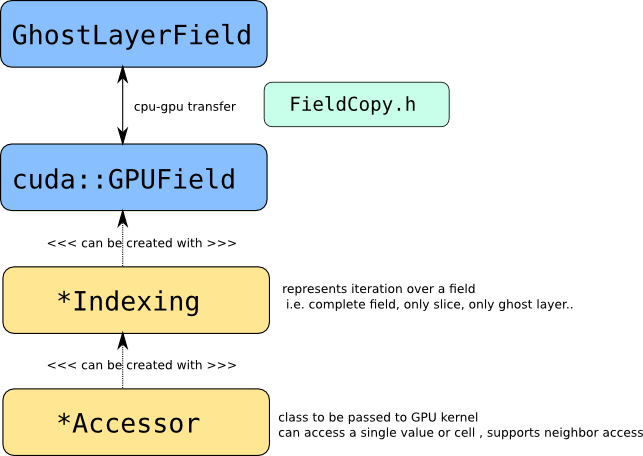
When writing a kernel that operates on a field, the first task is to distribute the data to threads and blocks. We need a function $(blockIdx, threadIdx) \rightarrow (x,y,z)$ or $(blockIdx, threadIdx) \rightarrow (x,y,z,f)$. The optimal mapping depends on many parameters: for example which layout the field has, the extends of each coordinate, hardware parameters like warp-size, etc. Thus this indexing function is abstracted. A few indexing strategies are already implemented which can be substituted by custom strategies. A indexing strategy consists of two classes: and somewhat complex Indexing class, which manages the indexing on the host-side and a lightweight Accessor class, which is passed to the GPU kernel.
An indexing scheme is very similar to the iterator concept, it defines the bounds of the iteration, which is not necessarily the complete field but could also be a certain sub-block, for example the ghost layer in a certain direction.
Lets start to write a simple kernel that doubles all values stored in a field:
We do not have to care about indexing, the gpu::FieldAccessor takes care of that. So this is a generic kernel that operates on double fields. Using the gpu::FieldAccessor the current and neighboring values can be accessed and manipulated.
This kernel can be called like this:
In the example above we only iterate over a slice of the field. Of course we can also iterate over the complete field, there are various static member functions in a Indexing class to create certain iteration patterns. The Indexing class encapsulates the information of how to launch the kernel (blockDim and gridDim) and holds the Accessor class that is passed to the kernel.
Two indexing strategies are currently provided: